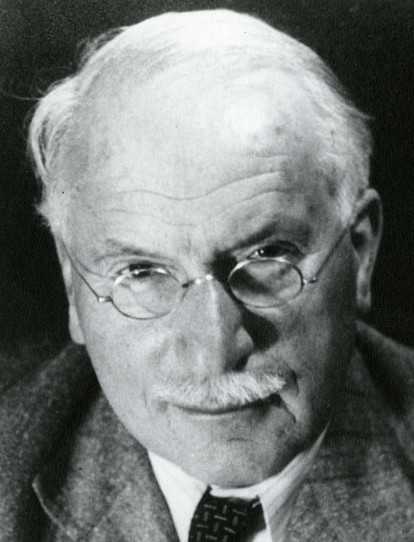
Carl Gustav Jung
The Center for the History of Medicine is happy to announce that the audio recordings of the C. G. Jung Biographical Archive have been digitized and are now available to researchers. Previously accessible only in transcript form, the collection consists of 181 interviews with Jung’s family, friends, colleagues, and contemporaries. The interviews, which took place from 1968 to 1972, were funded by the Francis G. Wickes Foundation and were conducted by Dr. Gene F. Nameche. The collection was donated to the Francis A. Countway Library of Medicine in 1972. A mentee of Sigmund Freud, Jung was a leader in dream analysis and is credited with founding the field of analytical psychology.
Due to restrictions set by the interviewees, some interviews are closed to access. In addition, access to the entire collection is restricted to onsite use only. For more information regarding access, please contact the Public Services staff.
The digitization of the Jung Biographical Archive was supported by the Carl Gustav Jung Fund, created at the time of the collection’s donation to ensure its longterm research use and accessibility.

The earliest surviving lectures from Harvard Medical School (H MS b3.13, Harvard Medical Library in the Francis A. Countway Library of Medicine)
Partially in the handwriting of Dr. John Warren (1753-1815), this volume of lecture notes on anatomy, beginning in December 1783, is the earliest surviving record of teaching at Harvard Medical School. Warren’s plan for medical study had been adopted by the Harvard Corporation on September 19, 1782, and he became the first faculty member appointed at the Medical School. These lectures were delivered in Harvard Hall, on the Cambridge campus.
After summarizing the history of his subject, Dr. Warren then justifies dissection as an essential component to anatomical study: “At the first view of dissections, the stomach is apt to turn, but custom wears off such impressions. It is anatomy that directs the knife in the hand of a skilful surgeon, & shews him where he may perform any necessary operation with safety to the patient. It is this which enables the physician to form an accurate knowledge of diseases & open dead bodies with grace, to discover the cause or seat of the disease, & the alteration it may have made in the several parts.”
The lecture notes were bequeathed to Harvard in 1928 by Dr. John Warren, the great-grandson of the first Warren. Through the generosity of Dr. Susan C. Lester, Assistant Professor of Pathology, and the Manual of Surgical Pathology Fund at Brigham and Women’s Hospital, the volume was recently conserved and then digitized in its entirety and is now available from the HOLLIS catalog at http://nrs.harvard.edu/urn-3:HMS.COUNT:4435974.